-
FlexAttention논문 정리/Fundamental 2025. 3. 12. 22:50
https://pytorch.org/blog/flexattention/
FlexAttention: The Flexibility of PyTorch with the Performance of FlashAttention
pytorch.org
FlashAttention을 어떤 모델에 적용하는 issue를 해결하다가 FlexAttention을 발견하게 됐다.
이것을 발견하게 된 것은 다음과 같다.
issue를 해결하다보니 FlashAttention을 적용한 모델과 적용하지 않은 모델의 결과가 다르게 나왔다. 이유는 다양할 수 있다. 이유를 파고들다보니 FlashAttention에서 attention mask가 적용되지 않는다는 것을 알게 되었다. 아래 링크에서 확인할 수 있다.
https://github.com/Dao-AILab/flash-attention/issues/352
[v2] Attention Masking · Issue #352 · Dao-AILab/flash-attention
Is any plan to add attention masking support? PyTorch's version of flash attention v1 included the ability to provide an attention mask in their implementation and it would be very useful to have t...
github.com
또한 위 링크를 통해 FlexAttention을 알게 되었다. 그래서 오늘은 FlexAttention을 정리하고자 이 포스팅을 쓰게 됐다.
사실 나는 FlashAttention도 잘 모른다. 기존의 Attention 계산을 해치지 않으며 메모리와 속도면에서 좋다는 것은 알고 있었지만, 어떤 원리일지 좀 알아보고 싶어졌다. 논문을 읽어볼 시간은 없어서 블로그를 참고해서 적어보았다.
FlashAttention

SRAM이 제일 빠르고, DRAM이 제일 느리다. 
위 그림과 같이 HBM에 접근하는 횟수를 줄인다. Tiling과 Recomputation 전략을 사용한다.
그 전에 일단 기본 Attention을 알아보자면, 아래와 같다.

1. Q, K가 HBM에서 로드돼서 S가 계산되고 HBM에 저장됨.
2. S가 HBM에서 읽어져서 P(probability)를 계산하고 HBM에 저장됨.
3. P, V가 HBM에서 로드돼서 O가 계산되고 HBM에 저장됨.
이렇게 6번 HBM에 접근해야 한다.
FlashAttention에서는 Tiling과 Recomputation을 사용한다.
Tiling은 아래와 같이 전체 행렬을 로드하는 게 아니라 작은 블록을 분할하여 순차적으로 처리하는 방식이다. 메모리 최적화와 병렬처리를 향상시킬 수 있다.

Recomputation은 forward pass에서 계산된 중간 결과를 메모리에 저장하지 않고 역전파에서 필요할 때 다시 계산하는 방법이다. 계산(FLOPs)는 증가하지만, HBM에서 데이터를 다시 읽어야 하는 횟수가 줄어들어서 속도가 향상된다.
FlashAttention2
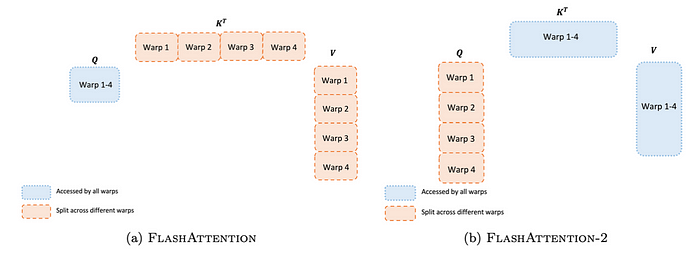
FlashAttention2는 non-matmul 연산 최적화와 Q 분할 방식 변경을 통해 성능을 개선함.
1. Non-matmul 연산 최적화
GPU에서 행렬 곱셈(Matmul) 연산은 매우 빠르게 실행되지만, 비(非) Matmul 연산(예: scaling, normalization 등)은 훨씬 느림.
기존 FlashAttention에서는 Re-scaling 연산을 여러 번 수행 → 연산 속도 저하 발생
FlashAttention 2에서는 Re-scaling 연산을 최소화하고, Memorization m, l 대신 L을 저장하여 최적화
→ Non-matmul 연산 감소로 속도 향상
2. Q 분할(Splitting) 방식 개선
기존 FlashAttention에서는 Key(K)와 Value(V)를 분할하여 연산하였음.
K와 V를 분할하면 중간 계산 결과를 동기화(synchronization)해야 함 → 연산 속도 저하
K, V가 아닌 Query(Q)를 분할(split)하는 방식으로 변경
K와 V는 공유하도록 설계하여, 중간 결과를 계속 동기화할 필요가 없음
→ 불필요한 동기화 비용을 줄여 연산 속도 개선FlexAttention
챗지피티가 적어줬습니다.
🔹 1. 기존 FlashAttention의 문제점
FlashAttention 같은 최적화된 어텐션 구현은 성능을 크게 향상시키고 긴 컨텍스트 처리도 가능하게 만들었지만, 유연성이 부족한 문제가 있음.
📌 기존 방식의 한계:
- PyTorch에서 간단한 연산자를 조합하여 **새로운 어텐션 변형(variant)**을 실험하기 어려움.
- 기존 최적화된 커널(Fused Kernels)에 포함되지 않은 어텐션 변형은 속도가 느려지고 CUDA OOM(메모리 부족 오류)에 걸릴 위험이 큼.
- 연구자들은 새로운 어텐션 기법을 실험하려면 새로운 커널을 직접 만들어야 함 → 개발 비용 증가
📌 어텐션 변형(variants)의 예시:
- Causal Attention (GPT 스타일)
- Relative Positional Embeddings (위치 정보 보정)
- Alibi (확장 가능한 위치 인코딩)
- Sliding Window Attention (윈도우 기반 계산)
- PrefixLM (미리 정해진 Prefix 토큰 처리)
- Document Masking / Sample Packing / Jagged Tensors
- Tanh Soft-Capping
- PagedAttention (효율적인 메모리 사용)
➡ 문제는 이러한 어텐션 기법을 조합해서 사용할 때 기존 커널이 이를 지원하지 않는다는 점!
➡ 예를 들어, Sliding Window Attention + Document Masking + Causal + Context Parallelism 같은 조합을 만들고 싶어도 기존 FlashAttention 커널에서는 지원되지 않음.결과: 연구자들이 원하는 어텐션 변형을 만들고 실험하는 것이 매우 어려워짐.
🔹 2. FlexAttention: 해결책!
이 문제를 해결하기 위해 PyTorch의 새로운 API인 FlexAttention을 도입.
✅ FlexAttention의 특징:
- 유연한 API 제공 → 다양한 어텐션 변형을 몇 줄의 PyTorch 코드로 구현 가능.
- FlashAttention 커널로 자동 변환 → torch.compile을 이용하여 최적화된 FlashAttention 커널을 생성.
- 메모리 최적화 → 추가 메모리 할당 없이 기존 수작업 커널과 유사한 성능 제공.
- 자동 역전파 지원 → PyTorch의 autograd 기능을 활용해 역전파(backpropagation) 자동화.
- 희소성(Sparsity) 활용 → 어텐션 마스크의 희소성을 최적화하여 성능 개선.
➡ 결과: 연구자들은 복잡한 커널을 직접 작성할 필요 없이, FlexAttention을 통해 다양한 어텐션 변형을 쉽게 실험 가능! 🚀
🔹 3. FlexAttention 예제 및 추가 정보
- FlexAttention 예제 모음: Attention Gym
- 새로운 어텐션 기법을 구현하고 싶다면? → 예제 제출 가능!
💡 추가 정보:
- FlexAttention은 기존 PyTorch 인프라를 적극 활용하여 최적화됨.
- PyTorch의 torch.compile과 FlashAttention 커널 자동 생성 기능을 결합하여 연구자들에게 강력한 실험 환경 제공.
✅ 결론: FlexAttention이 왜 중요한가?
✔ 기존 FlashAttention은 성능은 뛰어나지만, 새로운 어텐션 변형을 실험하기 어려웠음.
✔ FlexAttention은 연구자들이 쉽게 새로운 어텐션 변형을 추가하고 실험할 수 있도록 지원.
✔ 커널을 직접 작성하지 않고도 FlashAttention 수준의 최적화된 성능을 얻을 수 있음.
✔ 희소성(sparsity) 활용 및 메모리 최적화로 기존 어텐션 구현보다 훨씬 효율적.➡ FlexAttention 덕분에 어텐션 연구는 이제 "상상력만이 한계" 🚀