-
CyberHost: A One-stage Diffusion Framework for Audio-driven Talking Body Generation논문 정리/Visual Generation 2025. 3. 11. 14:55
Gesture까지 하는 Talking head generation 모델이다.
핵심 방법론은 다음과 같다.
1. Region Codebook attenion
- 사람의 손과 얼굴 관련 코드북을 이용하여 생성의 품질을 높임.
2. 여러가지 학습 전략
- Body Movement Map: 이는 사람의 몸의 이동 범위를 제어하는 데 사용되며, 주요 관절 (흉부 등)의 움직임을 가이드합니다.
- Hand Clarity Score: 손의 이미지가 모호해질 가능성을 줄이며 손의 구조적 세부 사항을 보존합니다.
- Pose-aligned Reference Feature: 이 기능은 입력 이미지의 골격 구조에 따라 변환된 특징을 활용하여 시각적 일관성을 유지하도록 돕습니다.
- Local Enhancement Supervision: 이 보조 손실 함수는 손과 얼굴 같은 지역의 내부 구조적 정보를 학습하는 데 유용합니다.3. 데이터 수집
200 시간 이상의 비디오 데이터와 10000개 이상의 신원으로 구성됨.
Introduction


audio-driven body animation
1. face, hand와 같은 부분을 잘 못함
2. audio와 body animation의 correlation이 낮음. audio를 condition으로 주면 uncertainty 높아짐.
관련 연구들
1. video-driven setting
- skeleton prior를 이용하여 model은 texture reconstruction에 집중하도록 함.
- pose template을 생성하는 motion generation module이 있고, retargeting technologies를 사용해야 돼서 inconvenient함.
2. 2stage를 이용하는 audio-driven setting
- audio-to-pose, pose-to-video
- system complexity 문제, learning efficiency 문제
- limited expression
- inaccurate pose, mesh가 모델의 성능 떨어뜨림.
따라서 body 생성 성능을 좋게 하는 one-stage framework가 필요함.
One-stage audio-driven body animation framework
- Region codebook attention. learnable spatio-temporal memory bank as motion codebook.
- 입력으로 body movement map과 hand clarity score이 control condition으로 들어가서 body movement와 hand motion을 control함.
- skeleton map을 사용하여 pose align 맞춤.
- auxiliary keypoint loss와 local reweight loss를 region supervision으로 사용하여 local region에 대한 생성을 좋게 함.
1. one-stage
2. region codebook attention
3. human-prior-guide trainingRelated work
body animation 쪽은 잘 모르는 부분이어서 정리해보았다.

기존의 Body animation 연구를 보면
Diffusion을 사용하고, 2D U-Net에서 3D로 옮겨간다.
AnimateAnyone은 skeleton map을 diffusion의 control signal로 사용한다.
Speech2Gesture은 gesture sequence를 생성한느 모델이다.
Vlogger은 2 stage 모델계속 2stage 모델이 제한적이라서 안좋다고 하지만 왜 안좋은 건지 잘 모르겠다.
Method
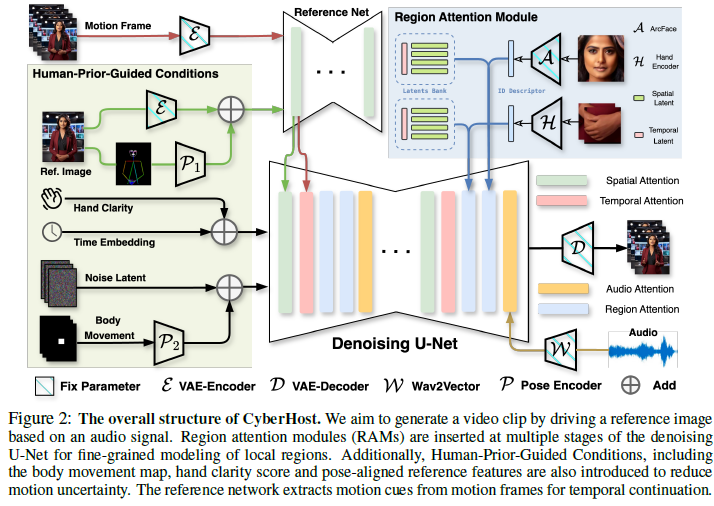


Region Attention Module(RAM)
- spatial-temporal region latents back
- identity descriptor extracted from cropped local images.
Several conditions
- body movement map: stabilize the root movement of the body.
- hand clarity score
- pose encoder: encode reference skeleton map.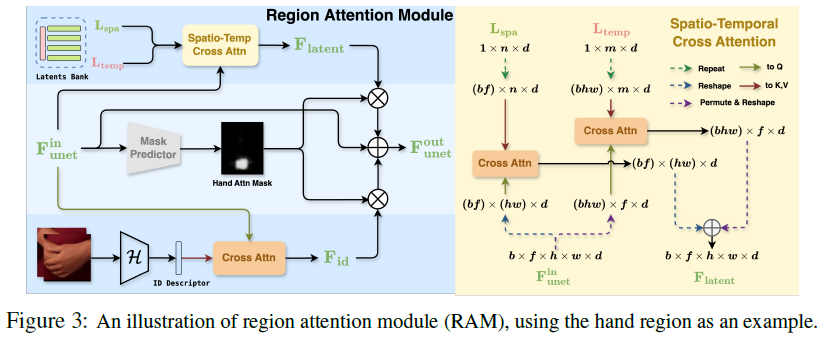

finegraine texture details이나 complex motion patterns을 잘 생성하지 못하는 이유는 explicit control signals이 없기 때문이다.
그 문제를 해결하기 위해 RAM을 사용했다.
RAM에는 spatio-temporal region latents back와 identity desciptor가 있다.
spatial dimension과 temporal dimension의 cross attention 진행.
body part position에 대한 prior information의 부재로 인해 auxiliary convolutional layers를 regional mask predictor로 사용함.
- regional attention mask를 추측하는 역할.
- 학습할 때 region dete cion boxes를 이용하여 superision signal을 생성함.

Identity descriptor를 이용해서 생성함. 
Local enhancement supervision을 통해서 더 정교하게 표현 
Artifacts
1. random global body movements
2. blurred hand gestures
- 위 두 개는 motion uncertainty in audio-driven generation
3. ambiguous limb structures.
- insufficient prior knowledge
이 연구에서는 아래 방법들로 audio와 body motion의 약한 correlation으로 인해 생기는 motion uncertainty를 줄였음.
- human prior information to the model
1. body movement map
2. hand clarity score conditions
3. pose-aligned reference feature를 이용하여 사람의 structure를 잘 이해하도록 하기도 함.

많은 몸동작은 학습을 어렵게 함.
body movement map을 이용하여 movement를 control
- Pose Encoder를 통해 얻는다.
rectangular box를 이용하여 움직임의 범위를 제한하는데, 넉넉하게 준다.
너무 뻣뻣하게 움직이는 것을 막는다.
Exposure duration과 rapid hand movement때문에 손이 잘 생성 안됨.
Hand clarity score를 condition으로 주어서 학습함.
Laplacian operator로 laplacian standard deviation을 측정하여 값이 높으면 선명한 것으로 보고 이 값을 사용함.
Inference할 때는 high clarity score를 이용하여 생성함
Reference net은 hand gesture를 정확하게 인식하지 못함.
Pretrained model을 이용하여 pose recognition을 하고 skeleton map을 얻음.
topological structure information을 포함하는 reference feature를 얻을 수 있음.Experiments

2 stage로 나눠짐.
1 stage에서는 인간 이미지 생성 과정 익힘
2 stage에서는 비디오 생성
각 비디오 클립은 12프레임으로 구성되고, motion frame은 4프레임으로 설정됨.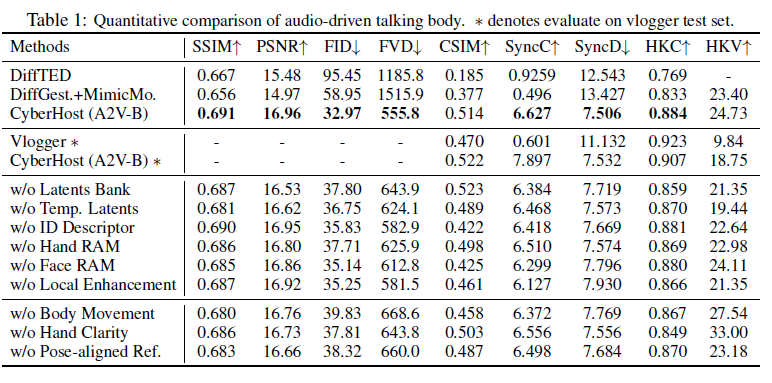
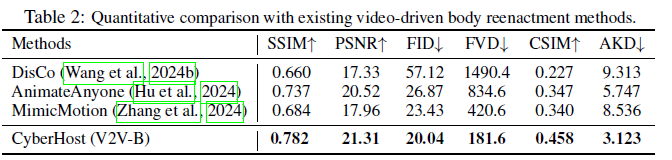
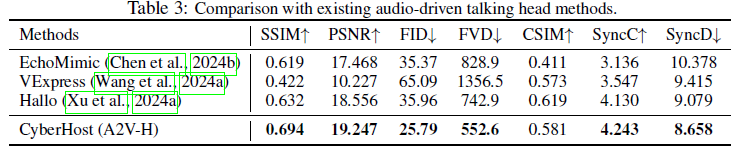
FID: 프레임 품질
FVD: 비디오 품질
CSIM: 외형 보존, 코사인 유사도
SyncC, SyncD: 오디오와의 동기화 품질
HKC: hand quality
HKV: hand diversity
2 stage와의 비교를 위해 SOTA 모델 이용 구현방법이 궁금했던 것이기 때문에 나머지는 넘어갈게요.
다음으로 읽을 논문들은 omnihuman이랑 이 논문에서 나오는 audio-driven talking body 모델인 DiffTED, Vlogger 등이 될 거 같아요.